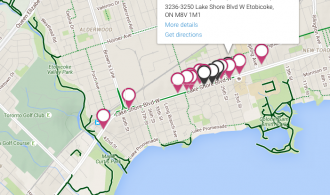
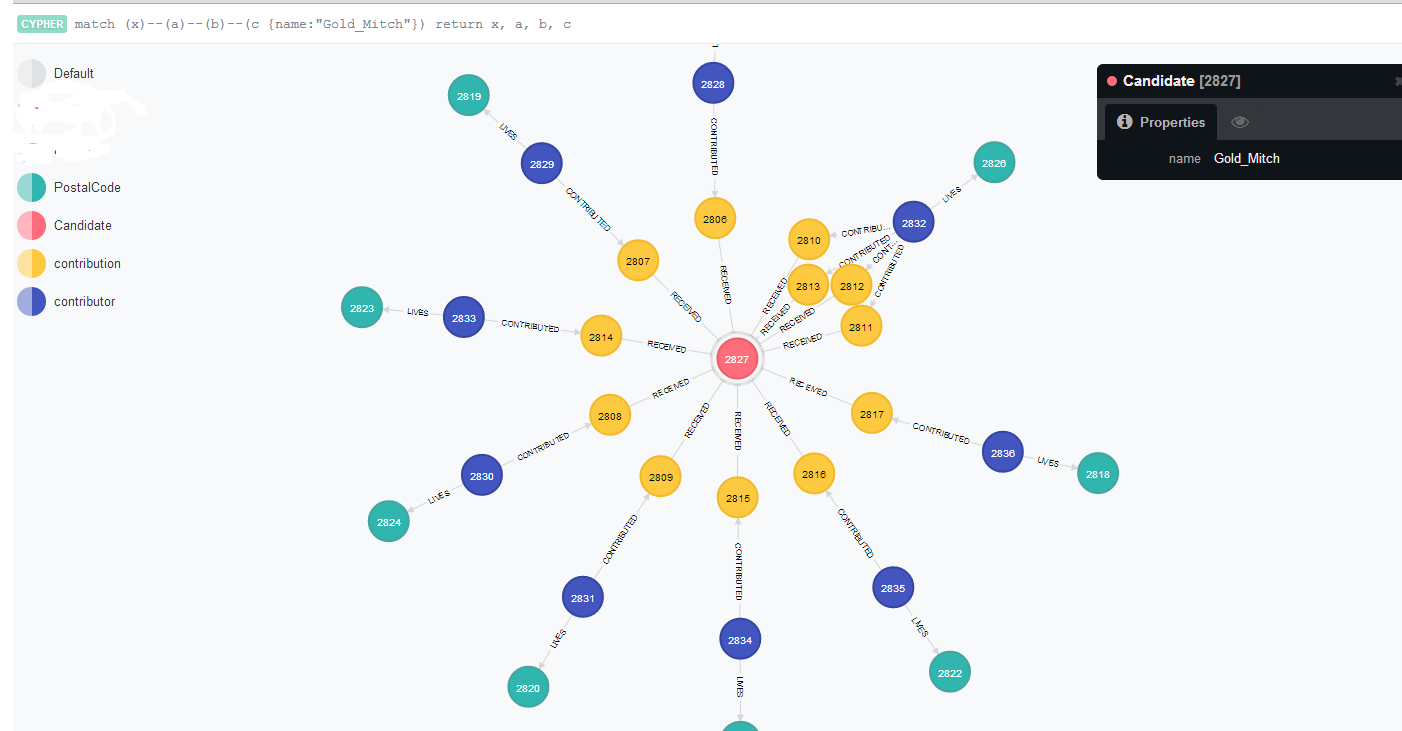
In my last post, I took some campaign contribution data and plugged it into Neo4j using a sweet Python plugin called py2neo. Now we’re going to take that same graph and give it some added value, namely flesh out the geospatial aspect of it.
Getting back to the example from last time, if you take a nice close look, you’ll see that there are postal codes. What’s missing?

….that’s right: You have all these postal codes, but you can’t really do that much with them because you don’t have any distances between them. If you want to do any analysis around concentrations of neighborhoods, or if you are a candidate and want to save on travel time, it’s really hard to do the way it is, now. So let’s add some distance data between the postal codes and add it to our graphs.
I decided to use the MapQuest API for this, mainly because the plugin (mapq for Python) is dead easy to get going. Unfortunately, I got some wonky results, probably because I didn’t have complete address data. If I was going to do this “for real” I would probably get better address data or use a plugin that can handle incomplete postal codes better.
The steps are as follows (after you’ve created the graph, natch):
- Get your MapQuest API key
- Get a unique list of postal codes
- Loop through each postal code, getting the province and city data, if available
- For each postal code, get the longitude and latitude using the MapQuest API
- Using itertools, get all the combinations of coordinates, getting the distance for each
- Feed the distances for each combination into Neo4j
Part 3 of this series is going to do some analysis using Cypher, but for now, let’s get the data loaded!
import csv
import py2neo
from py2neo import neo4j, node, rel #this is a handy add-in for working with Neo4j
import mapq
import time ## Optional. Add this if you want to create a delay on the API call
import itertools
mapq.key('xxxxxxxxxxxxxxxxxxxxxxx')
source = 'C:\Users\jlalonde\Documents\personal\elections\\tblMayor.csv' #obviously you want to adjust your path to suit what you need
codes = [] #this is your list of postal codes
coordinates = [] #this will be the postal codes, plus lat-lon
distances = [] # this will be the final list of postal codes plus distances from one another
fs = ['K','L','M','N'] #these will help to filter on Ontario postal codes
x = 0
with open(source, 'rb') as csvfile:
#for this loop you just need unique postal codes. Let's do it!
s = csv.reader(csvfile, delimiter=';')
for row in s:
#row[2] is the address, but it is not filled out most of the time
#row[3] is the contributor postal code
if row[11] == 'Gold, Mitch': #I'm just using Mitch Gold the candidate for this example.
codes.append([row[3], row[2]])
codes.sort()
# print codes
codes_unique = list(codes)
codes_unique.sort()
for p in codes_unique:
if p[0][:1] in fs:#this is to distinguish between Ontario and Quebec
prov = ', Ontario, '
else:
prov = ', Quebec, '
if len(p[1]) > 1: #this asks if there is address data
c = p[1].split(', ')
city = ', ' + str(c[-1]) #if there is append the city
else:
city = '' #otherwise, leave this blank
m = str(p[0]) + city + prov + 'Canada' #you are creating the
# print m
if x < 50:
t = mapq.latlng(m)
single = [p[0], t.get('lat'), t.get('lng')]
coordinates.append(single)
x = x + 1
#time.sleep(1) #a one-second delay for pinging mapquest API
combinations = list(itertools.combinations(coordinates, 2))
print combinations
Up until this point you now have all the possible combinations of postal codes, along with their longitude and latitude. Next up is to get the distances and then plug them in. FYI a BIG thank you and shout out to Michael0x2a for his code on StackExchange on distances.
from math import sin, cos, sqrt, atan2, radians
graph_db = neo4j.GraphDatabaseService()
R = 6373.0
for i in combinations:
if i[0][0] != i[1][0]:
lat1 = radians(i[0][1])
lon1 = radians(i[0][2])
lat2 = radians(i[1][1])
lon2 = radians(i[1][2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = (sin(dlat/2))**2 + cos(lat1) * cos(lat2) * (sin(dlon/2))**2
c = 2 * atan2(sqrt(a), sqrt(1-a))
distance = R * c
#print "Result of ", str(i[0][0]), " to ", str(i[1][0]), " is ", str(distance) # from here you can see some distances are zero, which means bad data.
#my guess is the Mapquest API is having a hard time with just postal codes being thrown at it.
string2 = 'MATCH (p1 {p_name: "' + i[0][0] +'"}), (p2 {p_name: "' + i[1][0] + '"})'
string2 = string2 + ' CREATE UNIQUE p1-[:ADJ {distance: ' + str(distance) + '}]->p2'
print string2
query2 = neo4j.CypherQuery(graph_db, string2)
go2 = query2.execute()
Below is Mitch Gold's campaign contributions, but this time with the adjacencies between the different postal codes.

...and here are just the postal codes using MATCH a-[:ADJ]->b RETURN a, b